Advertisement
Saving data is a common step when working with Pandas, and CSV files are one of the easiest formats to use. They're human-readable, easy to share, and compatible with most software. Whether you're wrapping up an analysis or just breaking your work into smaller chunks, saving a DataFrame lets you keep progress and pass it along without losing structure. And pandas gives you more than one way to handle it.
There’s more than one correct approach to saving a DataFrame, and the method you choose can change depending on the goal—whether it's size, structure, encoding, or compatibility.
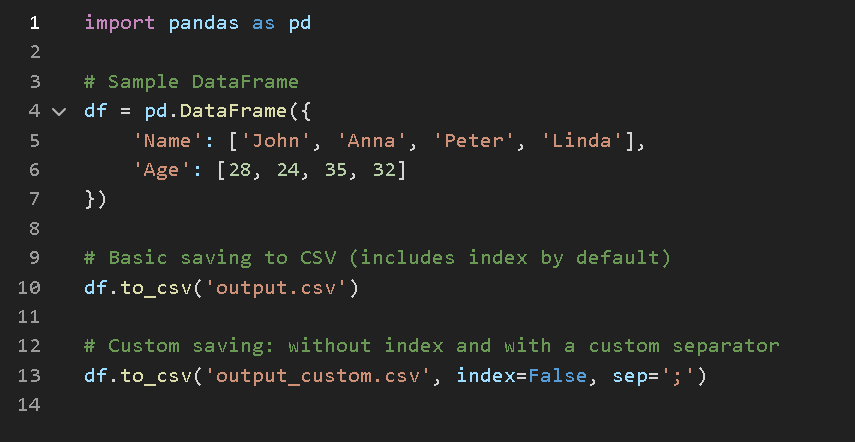
The simplest method to write a DataFrame is .to_csv(). You can start with:
python
CopyEdit
df.to_csv('data.csv')
By default, this includes the index, uses commas as separators, and writes the header row. If you want to keep your file clean and avoid including the index, especially if it's just a range, you can add:
python
CopyEdit
df.to_csv('data.csv', index=False)
That removes the index column entirely. If you want to write only certain columns or change their order, pass a list to the columns argument:
python
CopyEdit
df.to_csv('data.csv', columns=['name', 'age'], index=False)
This is helpful when your DataFrame has been processed or cleaned, and you only need to save a final selection.
You can also replace the default header with a custom one. Just be sure the number of custom headers matches the number of selected columns:
python
CopyEdit
df.to_csv('data.csv', header=['Full Name', 'Age'], columns=['name', 'age'], index=False)
If you prefer no headers at all:
python
CopyEdit
df.to_csv('data.csv', header=False, index=False)
This setup is common when the data will be read into another system that doesn’t need column names.
If your data contains commas (like addresses or descriptions), a different separator makes things cleaner. Tabs and semicolons are popular choices:
python
CopyEdit
df.to_csv('data.tsv', sep='\t', index=False)
df.to_csv('data.csv', sep=';', index=False)
You can also control the type of line ending. This might matter if you're generating files on Linux but sending them to a Windows system, or exporting to a tool that needs a specific terminator:
python
CopyEdit
df.to_csv('data.csv', line_terminator='\r\n')
These small formatting options make a difference when other systems are sensitive to CSV layout.
When working with international data or characters outside the standard ASCII set, encoding becomes important. pandas supports several:
python
CopyEdit
df.to_csv('data.csv', encoding='utf-8')
This works well in most cases. For Excel compatibility, especially with non-English characters, UTF-8 with BOM helps:
python
CopyEdit
df.to_csv('data.csv', encoding='utf-8-sig')
For legacy systems that don’t read UTF-8 properly, ISO-8859-1 (Latin-1) is another option:
python
CopyEdit
df.to_csv('data.csv', encoding='latin1')
If your data includes commas, quotes, or newlines inside fields, you can avoid broken CSV formatting by adding quoting:
python
CopyEdit
import csv
df.to_csv('data.csv', quoting=csv.QUOTE_ALL)
You can also use QUOTE_MINIMAL, QUOTE_NONNUMERIC, or QUOTE_NONE based on how strict the receiving software is.
While saving to a file is common, pandas lets you save to more than just flat CSVs. If you're working in a web app, writing to memory is often more efficient:
python
CopyEdit
import io
buffer = io.StringIO()
df.to_csv(buffer, index=False)
csv_content = buffer.getvalue()
This lets you use the CSV content without ever touching the disk—ideal for APIs or web services.
When file size matters, compressing the CSV makes it easier to store and transfer. pandas handles this directly without needing extra steps.
Gzip:
python
CopyEdit
df.to_csv('data.csv.gz', compression='gzip')
Bzip2:
python
CopyEdit
df.to_csv('data.csv.bz2', compression='bz2')
For .zip files:
python
CopyEdit
df.to_csv('data.zip', compression=dict(method='zip', archive_name='data.csv'))
Compressed files are still readable using pd.read_csv(), which makes them a good option for backups or large exports.
If you prefer clean file path management, especially in more structured projects, using Path objects from pathlib makes things clearer:
python
CopyEdit
from pathlib import Path
file_path = Path('outputs') / 'data.csv'
df.to_csv(file_path, index=False)
This avoids string concatenation and helps when building out folder structures dynamically.
Sometimes, you don’t want to overwrite your CSV. If you're saving in stages or adding rows from different batches, you can append instead:
python
CopyEdit
df.to_csv('data.csv', mode='a', header=False, index=False)
Make sure you skip the header, or it will repeat every time.
You can also save a filtered version of your DataFrame—helpful when you're interested in saving only a portion of your data without changing the original:
python
CopyEdit
filtered = df[df['score'] > 70]
filtered.to_csv('filtered_data.csv', index=False)
This lets you break out specific parts of your dataset for separate use, sharing, or archiving, without extra manipulation of the full DataFrame.
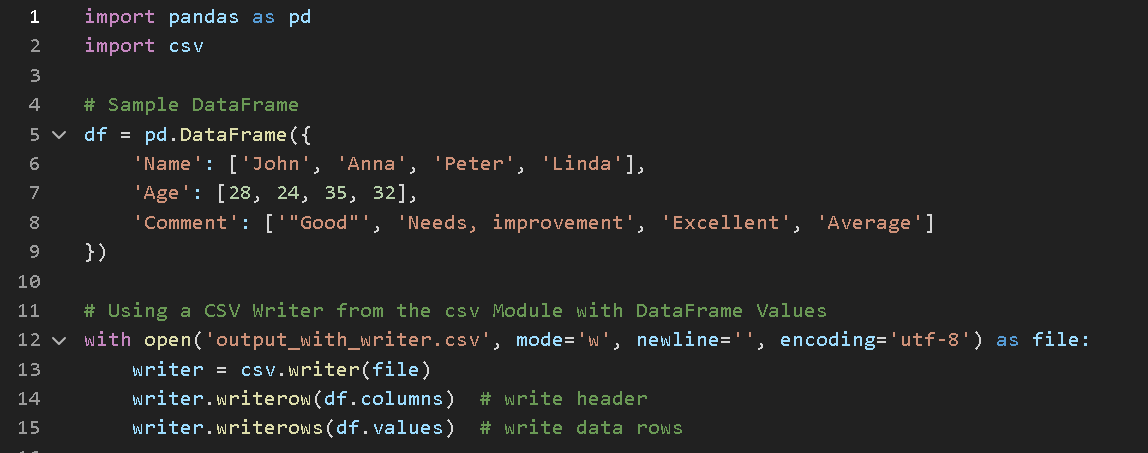
Although pandas has built-in CSV handling, you can bypass .to_csv() entirely and use Python’s built-in csv module. This gives you more control if you're integrating with custom systems or applying extra logic row by row.
python
CopyEdit
import csv
with open('data.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(df.columns) # Write headers
writer.writerows(df.values) # Write rows
This method uses df.columns to write the header and df.values to write the data as a list of rows. It’s not as flexible as .to_csv() for things like encoding or quoting, but it gives you complete control over the writing process. It's also useful in cases where you're looping over DataFrame rows and adding logic before writing each row.
There isn’t just one way to save a pandas DataFrame as a CSV. The method you choose depends on whether you're thinking about file size, character sets, compatibility, layout, or performance. In some situations, you need a quick .to_csv() with no extras. Others require attention to separators, encodings, or quoting to keep things clean and usable.
Once you're aware of the options pandas gives you, saving becomes more than just a technical step—it becomes a way to shape your data so that it's ready for whatever comes next. Whether you’re writing to a local file, memory buffer, or compressed archive, pandas gives you the tools to make that choice confidently.
Advertisement

Learn how __init__ in Python works to initialize objects during class creation. This guide explains how the Python class constructor sets instance variables, handles defaults, and simplifies object setup
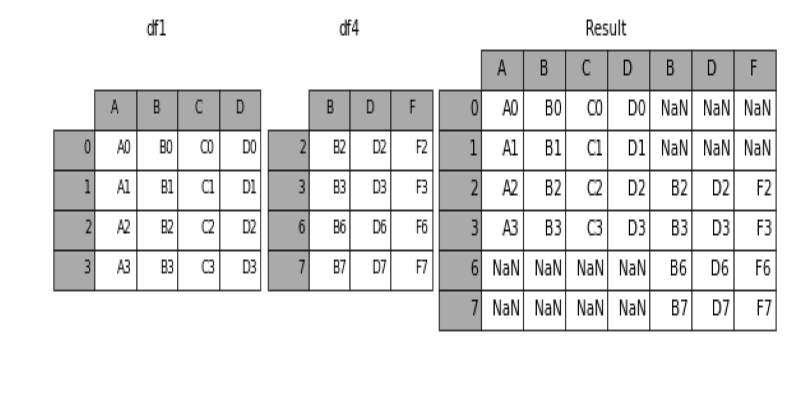
Learn how to concatenate two or more DataFrames in pandas using concat(), append(), and keys. Covers row-wise, column-wise joins, index handling, and best practices
Highlighting top generative AI tools and real-world examples that show how they’re transforming industries.
Learn how to loop through dictionaries in Python with clean examples. Covers keys, values, items, sorted order, nesting, and more for efficient iteration

Explore how developers utilize the OpenAI GPT Store to build, share, and showcase their powerful custom GPT-based apps.

Discover how to install and set up Copilot for Microsoft 365 easily with our step-by-step guide for faster productivity.

Domino Data Lab introduces tools and practices to support safe, ethical, and efficient generative AI development.

Explore Pega GenAI Blueprint's top features, practical uses, and benefits for smarter business automation and efficiency.
Want to organize your pandas DataFrame without confusion? This guide shows clear, practical ways to sort by values, index, custom logic, or within groups

Discover top industries for AI contact centers—healthcare, banking fraud detection, retail, and a few others.

Compare Intel’s AI Gaudi 3 chip with Nvidia’s latest to see which delivers better performance for AI workloads.

Struggling with Copilot's cost or limits? Explore smarter alternative AI tools with your desired features and workflow.